
飞书深诺集团(https://www.meetsocial.com/)
是专注海外数字营销解决方案的综合服务集团,为中国出海企业提供可定制组合的全链路服务产品,满足游戏、APP、电商、品牌等典型出海场景需求,陪伴品牌应对海外市场的种种挑战。
技术背景:
在服务电商客户的场景下, 创意部门常常要为客户制作素材,如:广告图,宣传视频,宣传文案等。通过以图搜图, 以视频搜视频,文本搜文本的方式, 发掘素材,能够为设计人员提供创意上的参考。同时,也根据一些其他条件(比如热度,效果值等)作为辅助搜索的条件,帮助创意人员选择合适的素材。因此,利用Milvus向量检索引擎在内的一系列技术,为业务部门提供一个素材的综合搜索系统,就是此项目的动机。
技术选型:
由于业务接口需要实时返回,还需要承受一定程度的并发负载,因此我们认为milvus 是比较合适的向量检索工具。它对FAISS, ANN等工具进行了封装, 建立自己的存储文件结构, 同时提供了方便的服务化接口, 可以算的上开箱即用了。在保持检索速度快的同时, milvus可以通过参数设置,对向量检索的准确性,资源占用做一定的 tradeoff,比较适合在实际工程中使用。
我们在返回相似向量的同时, 还需要图片/视频的一些对应信息, 我们通过 kv的形式放在 redis 缓存里,加快获取的速度。在web接口封装方面,考虑到团队里python程序员占主流,我们选用了 nginx + flask + gunicorn + supervisor 的web经典套餐。
使用到的各工具和框架:
- Milvus (图片/视频/文本的向量相似检索)
- Redis (业务缓存)
- Nginx(负载均衡)
- Flask+Gunicorn (Web框架+并发服务)
- Supervisor (服务的进程启动与异常自动重启)
- Docker (容器隔离部署)
项目实现:
在我们的项目中,图片使用EfficientNet来提取特征向量,视频通过提取关键帧之后,再将每一帧图片进行向量提取之后叠加,文本采用BERT来做特征提取。
架构示意:
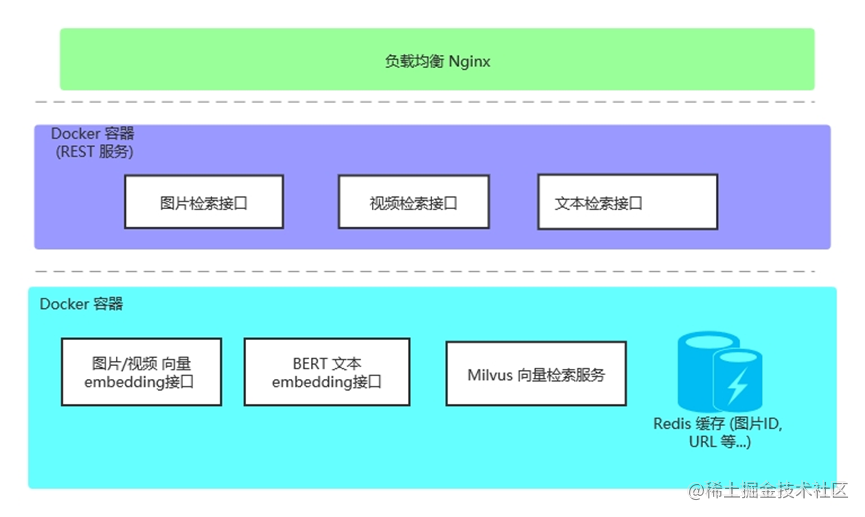
选择合适的索引:
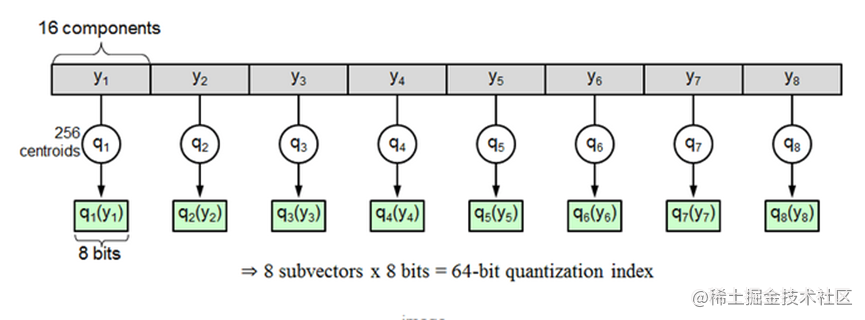
图片/视频/文本向量在检索出来之后, 上层调用还要做一些业务操作, 留给我们的接口的时间就不能太多, 要求做到1s内返回。由于对速度的要求比较高, 同时服务部署的机器内存又有一定的限制, 我们选用了 IVF_PQ 作为向量索引。这是一种有损压缩的向量索引, 它将所有向量分解成m段, 每一小段分别进行聚类,每小段由所属的聚类中心来表示,称为索引值。
如:一个D=128维的原始向量,它被切分成了M=8个d=16维的短向量,同时每个16维短向量都对应一个量化的索引值,索引值即该短向量距离最近的聚类中心的编号,每一个原始向量就可以压缩成8个索引值构成的压缩向量,即每个向量都用这8个索引值来表示,相对于原始值有一定的误差。
在实际使用的时候,预先计算好的各个聚类中心间的距离(codebook码表),通过查找表得出两个向量索引值之间的距离,来近似替代两个向量的真实距离,加快了计算速度;在使用中可以通过参数m的设置, 使得向量压缩成很小的比例, 也大量减少了内存占用(约为向量原始空间大小的5%~10%)。
根据milvus官方提供的公式:

我们计算得出合适的索引参数是 nlist=1024, m=8
使用分区提高速度:
目前素材中,图片接近4kw, 视频1kw,文本3kw, 为了提高检索速度, 分区变得十分必要。我们通过一些业务属性, 根据属性值做笛卡尔积操作来建立分区:
例如,我们向量对应的Item有两个属性:
属性A,取值 1, 2, 3, 4
属性B,取值 1, 2, 3
那么建立分区 A1_B1, A1_B2, A1_B3, A2_B1, A2_B2, A2_B3, …… A4_B3, 一共12个。通过分区操作,我们将每个分区的向量规模控制在500w以下, 进一步提高了检索速度。
需要注意的是, 用来建立分区的属性应该是不会变动的基本属性, 因为如果发生变动, 重新建立分区, 导入数据, 建立索引是非常漫长的过程, 所以分区确定下来, 轻易不要改变。另外分区及属性值不能太多, 否则各个属性值相乘(笛卡儿积)会让数量变得非常庞大, 使程序变得过于复杂. 更多的属性检索或筛选, 我们在milvus向量搜索的结果上另外封装一层业务接口来实现。
系统效果:
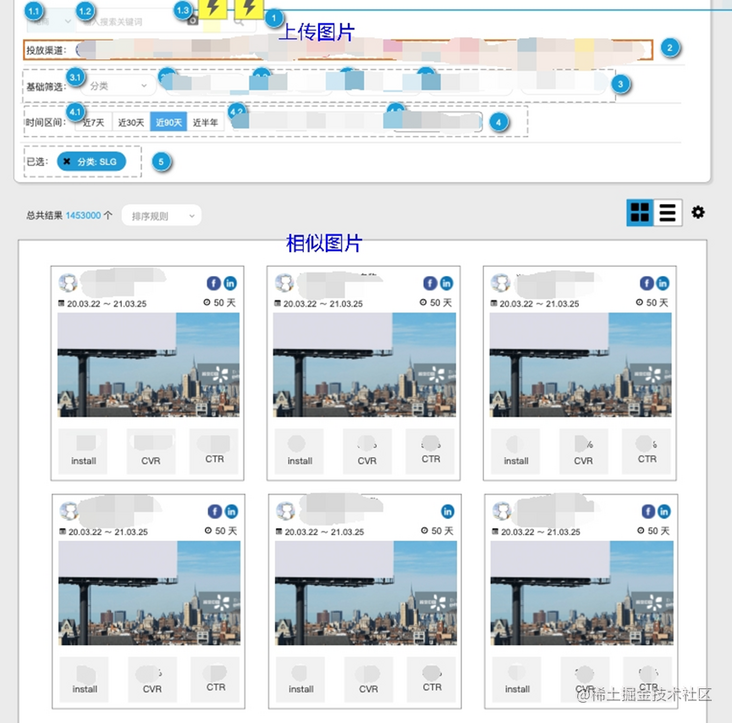
向量检索服务以REST接口的形式对外提供,前端团队调用接口,将结果展示在界面上。UI示意如图(部分业务信息模糊处理),类似谷歌的以图搜图,百度的以影搜影等
性能指标:
目前我们的图片总量大约在3kw+,视频总量大约在1kw,向量维数为2048维,文本3kw左右,768维。图片检索耗时0.2s左右;视频检索耗时0.1s左右;文本向量检索耗时
关于milvus的一些经验与总结:
milvus集成各种常见向量索引, 能满足工程中大部分的需求,存储操作和检索速度都达到了工业级的水准,提供服务化的接口, 基本上做到了开箱即用。不过milvus目前还不支持其他类型(字符型,整型)的属性检索(0.11版中有支持, 但后来在正式版1.0中取消了)。总体来说,对于需要快速构建向量检索服务,又不想花太大成本(ES,SOLR)的轻量级项目来说,Milvus是一个很好的选择。
参考文献:
Product quantization for nearest neighbor search. Hervé Jégou, Matthijs Douze, Cordelia Schmid
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
