
- 前言
-
9. 并发实践
- 9.1 context 的不恰当传播(#61)
- 9.2 开启一个协程但不知道何时关闭(#62)
- 9.3 在循环中没有谨慎使用协程(#63)
- 9.4 使用 select 和 channel 期待某个确定的行为(#64)
- 9.5 不使用用于通知的 channel(#65)
- 9.6 不使用 nil channel(#66)
- 9.7 对 channel 的大小感到疑惑(#67)
- 9.8 忽视 string 格式化的副作用(#68)
- 小节
前言
大家好,这里是白泽。《Go语言的100个错误以及如何避免》是最近朋友推荐我阅读的书籍,我初步浏览之后,大为惊喜。就像这书中第一章的标题说到的:“Go: Simple to learn but hard to master”,整本书通过分析100个错误使用 Go 语言的场景,带你深入理解 Go 语言。
我的愿景是以这套文章,在保持权威性的基础上,脱离对原文的依赖,对这100个场景进行篇幅合适的中文讲解。所涉内容较多,总计约 8w 字,这是该系列的第八篇文章,对应书中第61-68个错误场景。
当然,如果您是一位 Go 学习的新手,您可以在我开源的学习仓库中,找到针对《Go 程序设计语言》英文书籍的配套笔记,其他所有文章也会整理收集在其中。
B站:白泽talk,公众号【白泽talk】,聊天交流群:622383022,原书电子版可以加群获取。
前文链接:
-
《Go语言的100个错误使用场景(1-10)|代码和项目组织》
-
《Go语言的100个错误使用场景(11-20)|项目组织和数据类型》
-
《Go语言的100个错误使用场景(21-29)|数据类型》
-
《Go语言的100个错误使用场景(30-40)|数据类型与字符串使用》
-
《Go语言的100个错误使用场景(40-47)|字符串&函数&方法》
-
《Go语言的100个错误使用场景(48-54)|错误管理》
-
《Go语言的100个错误使用场景(55-60)|并发基础》
9. 并发实践
章节概述
- 防止发生 goroutine 和 channel 中的常见错误
- 理解标准数据结构在并发场景的使用
- 使用标准库和一些扩展
- 避免数据竞争和死锁
9.1 context 的不恰当传播(#61)
context 作为承载上下文的实例,经常在各个函数之间传播,由于 context.Context 本身是一个接口,它声明了四个方法:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() 当一个 context 因为过期或者被手动 cancel,都会导致上下文关闭。此时可以从 Done() 获得的 channel 中获得关闭信号,以及从 Err() 方法获得原因。
这也导致了,在传递 context 实例的时候,因为一些原因导致传递给子步骤的 context 已经关闭,但是子步骤中需要使用到,从而造成混淆。
假设有一个场景,针对收到的一个 HTTP 请求,服务端会处理一些任务,得到结果A,同时将处理结果A通过 Kafka 异步发送一个事件,同时主协程返回任务处理结果A给客户端。
func handler(w http.ResponseWriter, r *http.Request) {
response, err := doSomeTask(r.Context(), r)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
go func() {
err := publish(r.Context(), response)
// Do something with err
}()
writeResponse(response)
}
考虑以下三个场景:
- 客户端请求关闭
- 如果是 HTTP/2 的请求,当请求被取消
- 当 response 已经被返回给客户端
前两个场景,如果在执行完 doSomeTask() 的到 response 并调用 publish 后,请求被取消,则 publish 函数是可以允许接收一个被关闭的 context 实例的,只要在函数内判断当 context 被取消时,不发送消息即可。(当然不做任何处理,允许发送也是没有问题的)
但如果是已经将 writeResponse(response) 触发,响应给客户端,则 *http.Request 关联的 context 会被取消,此时如果在 publish() 函数中,做了 context 实例是否被取消的判断,则会出现混淆。因为此时是执行成功的链路,只是 go func() 执行逻辑因为异步的原因慢了,kafka 消息还是需要发送的。
解决方案:
type detach struct {
ctx context.Context
}
func (d detach) Deadline() (time.Time, bool) {
return time.Time{}, false
}
func (d detach) Done() 自定义 context 实例,将 Done() 和 Err() 方法失效,当不希望 context 的关闭对子步骤造成影响,可以通过这种方式,保留从原 context.Context 的实例中,获取上下文参数 value 的能力。
9.2 开启一个协程但不知道何时关闭(#62)
goroutine 泄漏:
协程启动将占用一个约 2KB 大小的栈内存空间,并随着使用增长或者收缩占用的空间,一个协程可以持有一个引用类型的变量,且分配在堆上。goroutine 也可以持有 HTTP 链接、数据库连接池等各种资源,如果协程发生了泄漏,则这些协程内原本应该被优雅释放的资源也将发生泄漏。
错误示例一:
ch := foo()
go func() {
for v := range ch {
//..
}
}()
在上述示例中,新创建的协程只有当主协程创建的 channel 被关闭的时候才会结束,但是如果外部没有主动关闭,则这个子协程会发生泄漏,永远无法关闭。
错误示例二:
假设应用执行之前需要通过一个函数去监听外部的配置信息。
func main() {
newWatcher()
// Run the application
}
type watcher struct{ /* Some resource */}
func newWatcher() {
w := watcher{}
go w.watch()
}
上述代码的问题在于,newWatcher 函数内启动的子协程会由于主协程的结束而被迫终止,导致 watcher 结构体所持有的资源,没有被优雅关闭。
错误示例三:
在错误示例二的基础上,容易犯的一个错误是,认为可以通过传递一个 context 来感知主协程关闭,从而控制子协程资源的释放。
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
newWatcher(ctx)
// Run the application
}
type watcher struct{ /* Some resource */}
func newWatcher(ctx context.Context) {
w := watcher{}
go w.watch(ctx)
}
错误原因:此时主协程如果关闭了传递给 watcher 结构体的 context,但是依旧有可能主函数直接执行完成,关闭了,子协程即使收到了 context 关闭的信号,依旧不一定有时间完成资源的释放。
⏰ 正确示例:
func main() {
w := newWatcher()
defer w.close()
// Run the application
}
func newWatcher() watcher {
w := watcher{}
go w.watch()
return w
}
type watcher struct{ /* Some resource */}
func (w watcher) close() {
// Close the resources
}
前几个示例出现资源释放问题的原因在于,在父协程关闭的时候,并没有阻塞等待子协程资源的释放,因此正确示例中,主协程在 return 之前,主动关闭 watcher 结构体持有的资源,实现优雅退出。
最佳实践:
将 goroutine 当作一种资源,在创建的开始就需要考虑何时关闭,并且如果 goroutine 持有了其他的资源,则需要一并考虑这些资源的释放。
如果要关闭主协程,务必将所有的释放工作,提前完成。
9.3 在循环中没有谨慎使用协程(#63)
错误示例:
s := []int{1, 2, 3}
for _, i := range s {
go func() {
fmt.Println(i)
}()
}
// 输出结果可能是:233,333
循环结构内部的 goroutine,这种闭包的写法,持有的 i 是同一个变量,因此虽然 i 是按照顺序1,2,3赋值的,但是并不能决定协程是在 i 等于几的时候触发打印操作。
比如出现233的执行顺序图示如下:
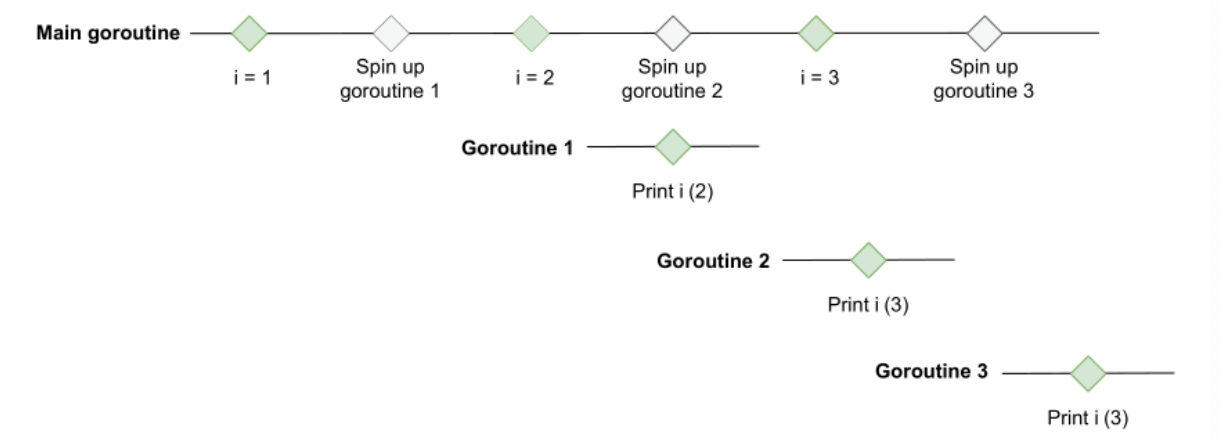
解决方案一:
for _, i := range s {
val := i
go fun() {
fmt.Println(val)
}()
}
通过引入 val 变量,可以确保 val 也是按顺序1,2,3进行赋值的,因为是局部变量,因此可以确保最终打印结果的有序。
解决方案二:
for _, i := range s {
go func(val int) {
fmt.Print(val)
}(i)
}
此时 goroutine 内部并没有直接引用外部的变量,此时 val 是输入的一部分,因此是一份新的拷贝,并不会引用同一个变量 i,所以依旧可以输出123。
9.4 使用 select 和 channel 期待某个确定的行为(#64)
假设需要同时监听两个 channel,一个 channel 获取消息,一个 channel 获取关闭信号:
for {
select {
// 此时 messageCh 是一个具有缓冲的 channel
case v := Go语言中:虽然 select 的两个 case,第一个获取 message 的 channel 排在前面,但是当多个条件同时成立的时候,执行是随机的,为了避免饥饿的情况。
为了能够顺利打印出所有的十个数,有两种方案:
- 将有缓冲的 channel 替换成无缓冲的 channel,这样使得消息的发送和接收成为了一个阻塞的串行流程,在完成所有数字的打印操作之前,主协程并不会执行
disconnectCh 这句代码。 - 使用单一的一个 channel 获取消息以及结束信号,用一个结构体作为 channel 的消息内容。
假设一定有多个消息的接收端,则通常来说,无法预测消息执行的顺序,一个可选的解决方案:
for {
select {
case v := 当触发关闭链接的时候,在一个新的循环中消费 messageCh 中剩余所有的 message,select 语句的 defalut case 当且仅当没有其他 case 匹配的时候会执行。
当然如果某一个时刻,还有协程即将向 messageCh 发送消息,但是 messageCh 此刻为空,则会执行 select/default case,导致未发送的 message 的丢失。
9.5 不使用用于通知的 channel(#65)
假设需要一个 channel,为另一个协程传递关闭链接的信号,此时可以通过如下实现:
disconnectCh := make(chan bool)
这种方式可以通过传递一个 true 字面量用于通知子协程关闭链接,但是 false 字面量是没有意义的,此时需要的只是一个信号,所以可以使用空的结构体实现:
disconnectCh := make(chan struct{})
空的结构体本身不占用额外的存储空间,但是可以达到传递信号的效果,是 Go 语言当中地道的用法。
使用 struct{} 作为占位,经常出现在其他场景中,比如创建一个集合:
set := make(map[K]struct{})
9.6 不使用 nil channel(#66)
nil channel 的特性:
var ch chan int
假设有这样一个场景,需要从两个 channel 中接收数据,并且合并两个 channel 的数据到另一个 channel,且另一个 channel 的 buffer 长度为1。
错误示例一:
func merge(ch1, ch3 这种情况下,必须等 ch1 所有数据全部读取完毕,才会读取 ch2 的,并不是一个并发模型。
错误示例二:
func merge(ch1, ch2 chan int) 使用 for/select 可以实现随机从两个 channel 中获取 v,但是问题在于,上述这种 for 循环将永远无法结束,即使外部可以控制将 ch1 和 ch2 都关闭了,但是面对两个关闭的 channel,select 的两个 case 的读取操作是不会阻塞的,依旧会读取出 0 值,并传递给 ch,导致 close(ch) 永远无法触发。
错误示例三:
func merge(ch1, ch2 chan int) 通过状态机的形式,控制当两个 ch 都关闭的时候,触发第三个 channel 的关闭。但是上述实现有一个问题,就是即使 ch1 或者 ch2 有一者关闭了,因为 select 的两个 case 依旧不是阻塞的,所以会出现浪费 CPU 进行空转的情况,比如 ch1 已经关闭了,但是 select 依旧是随机触发了 case1,导致在触发另一个 case2 之前,会出现重复进入 select 循环的情况。(因为必须两个状态都是 true 才会使得状态机触发 close(ch) 的逻辑)。
推荐方案:
func merge(ch1, ch2 chan int) 利用 nil channel 的阻塞特性(存入和取出元素都会阻塞),使得当任一 channel 关闭之后,直接设置为 nil,这样会导致这个关联的 select 的 case 将永远阻塞,不会触发,会强制依赖另一个 case 的读取情况,如果另一个 channel 也关闭了,设置为 nil,则 for 循环条件不满足,结束循环,可以触发 close(ch)。
9.7 对 channel 的大小感到疑惑(#67)
如果从简单控制协程之间的同步,可以选择无缓冲的 channel,因为使用带有缓冲的 channel 并不能完全控制多个协程的执行顺序。
哪些情况下使用带有缓冲的 channel 更好:
- worker 工作池模式,如果有多个协程充当 worker,消费任务,那么可以创建一个容量等价于 worker 个数的 channel 用于传递结果,或者发送任务。
- 限制资源的访问,可以通过带有缓冲的 channel 限制可以访问某个资源的协程的数量(请求数量),达到一种限流的效果。
但是本质来说,设置带有缓冲的 channel 的大小与当前业务息息相关,使用更大的 channel 意味着允许更多的协程进行合作,但是也会消耗更多的内存,同时协程的执行也会消耗 CPU 的资源,因此,需要权衡 Memory 和 CPU 的使用后决定 buffer 的 size。
9.8 忽视 string 格式化的副作用(#68)
在协程并发的场景中,string 格式化存在副作用,下面讲解两个场景。
- etcd 数据竞争
etcd 是一个基于 Go 语言实现的分布式的 key-value 存储,提供了接口用于集群间的数据变更监听和交互,例如:
type Watcher interface {
// Watch 监听通过一个 key 获得的 channel,然后从 channel 中获取需要监听的事件
Watch(ctx context.Context, key string, opts ...OpOption) WatchChan
Close() error
}
服务端需要提供一个结构体,实现 Watcher 接口,并为客户端提供服务:
type watcher struct {
// streams 持有所有所有活跃的 gRPC streams
streams map[string]*watchGrpcStream
}
func (w *watcher) Watch(ctx context.Context, key string, opts ...OpOption) WatchChan {
ctxKey := fmt.Sprintf("%v", ctx)
// ...
wgs := w.stream[ctxKey]
// ...
}
上述 API 基于 gRPC 的 streaming 操作,本质是用于客户端和服务端的通信。
其中 ctxKey 是 map 的 key,通过 context 的格式化得到,当使用通过 context.WithValue 创建的 context 进行格式化的时候,Go 会读取这个 context 中所有的 value 值,在这种情况下,开发者会发现 context 包含了可变的值,例如一个指向结构体的指针,因此在多个协程间传递的 context 的值可能会被某个协程修改,从而导致数据竞争问题,最终影响格式化的准确性。
这种情况下,推荐的解决方式是选择不使用 fmt.Sprintf 去格式化 map 的 key,以免发生 context 格式化 value 的问题,或者额外实现一个 context 类型,格式化可以确定的上下文的 value。
- 死锁
假设有一个 customer 结构体,提供了修改 age 的方法和格式化输出方法,且由于会被并发读写,因此使用读写锁保护:
type Customer struct {
mutex sync.RWMutex
id string
age int
}
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if age 死锁的场景:假设为顾客修改 age,设置了一个小于0的age,则会触发 fmt.Errorf 格式化输出错误,由于格式化 %v 的时候,会调用 Customer 的 String() 方法,由于写锁已经被占用,String() 无法获取读锁,导致死锁。
解决方案:
- 单元测试很重要,充分的单元测试可以检测出问题
- 改变锁的使用时机:先判断 age 非法,在修改 age 之前,再上锁。
func (c *Customer) UpdateAge(age int) error {
if age 当然,第一种写法,也并不一定会导致,打印错误信息的时候触发死锁,只要确保不在持有写锁的时候,去试图获取读锁即可:
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock()
defer c.mutex.服务器托管Unlock()
if age 上述情况下,在打印错误的时候,只需要使用 c.id,并不会触发 Customer 的 String(服务器托管) 方法,从而避免了死锁。
小节
你已完成全书学习68%,再接再厉。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
